

- cross-posted to:
- programming@programming.dev
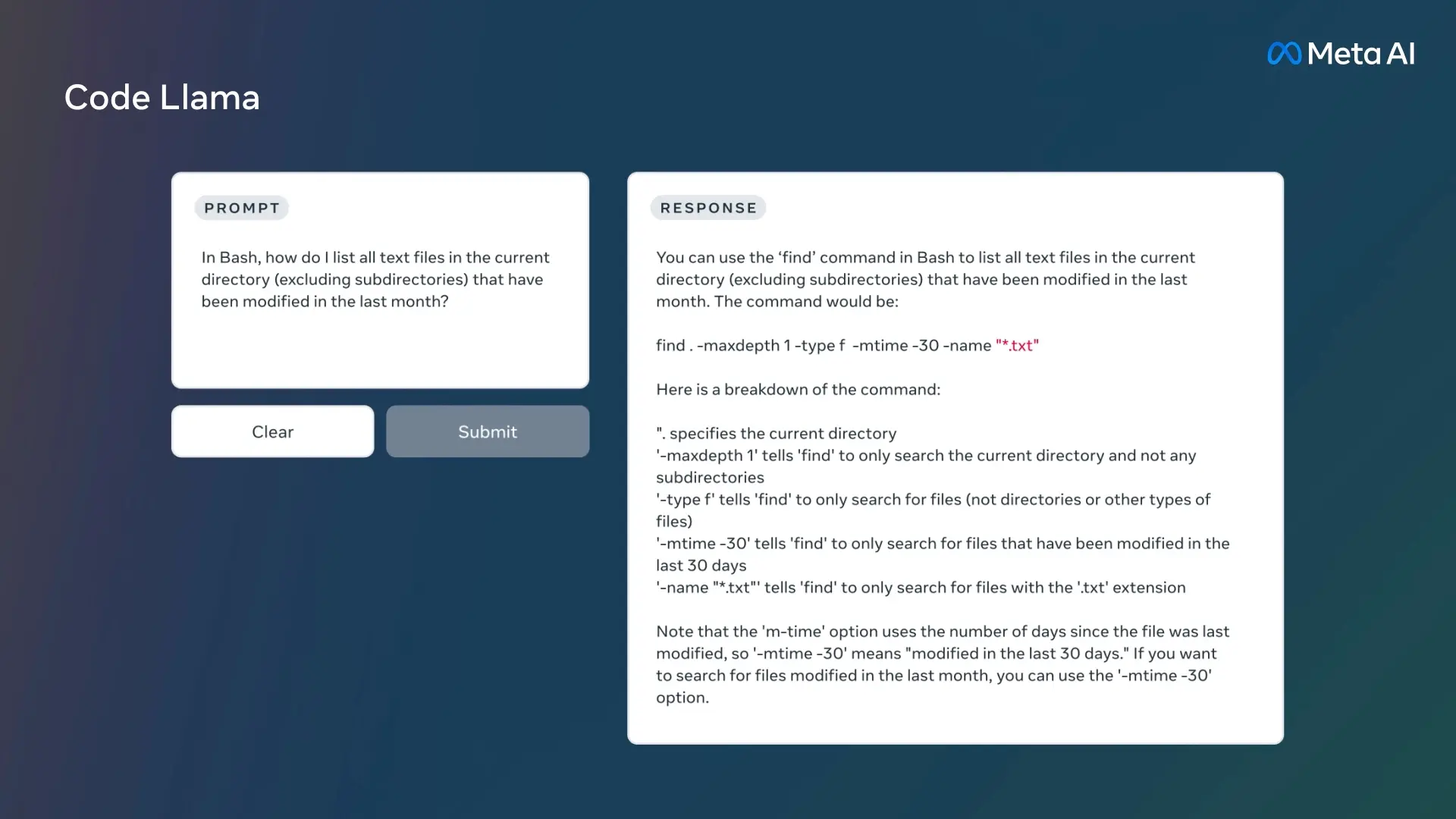
- cross-posted to:
- programming@programming.dev
cross-posted from !aistuff@lemdro.id
You must log in or # to comment.
Looks interesting, but doesn’t seem better than GPT-4. GPT-4 scored 67% on the Human Eval test, whereas Code Llama scored only a 53.7%, which isn’t a trivial difference. Bit disingenuous of Meta to claim it to be “on par” with ChatGPT.
They seem to qualify a bit below that they mean GPT-3.5-Turbo, which does often get referred to as ChatGPT (in contrast to GPT-4).